hello. i’m back with another bad idea ^-^
i found this thing called crucible. i’m going to run it in my home lab… forever.
this is probably inadvisable but i have been meaning to set up Ceph for a while and this is a little more wacky, which suits my more recent approach to sysadmin a little more :3
charlotte. what the hell is crucible
crucible is the storage system built by oxide computer company. it looks pretty neat.
oxide have this very specific allure to me for a couple reasons:
- they make the sickest fuckin computers i’ve ever seen
- i most certainly can never afford one of their sick fuckin computers
- transgender reasons
- they build stuff from the ground up!!! e.g. their system bringup literally does not have all the traditional UEFI firmware? they just boot?? somehow???
just look at this computer:

(img src: uhh i got this image from twitter. why are there not really any photographs of the oxide rack on the official website? there are only renders)
how does it work
chat. i do not work at oxide. but i have the code >:3
so here is what is up to the best of my knowledge:
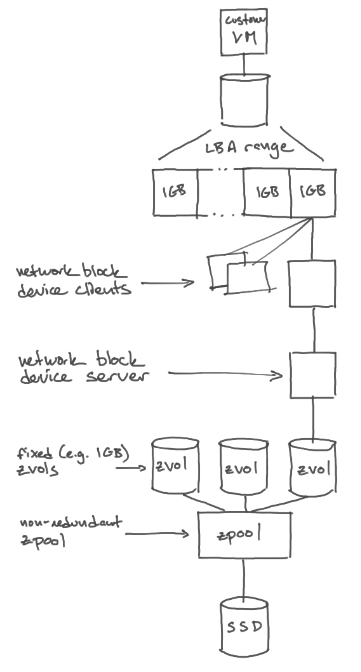
- this is block storage baby. we’re storing blocks
- crucible “downstairs” lives on the computer where the real physical block storage devices actually exist
- crucible “upstairs” lives on the computer where you want to access the virtual block storage (or on a hypervisor that the computer, like, lives inside?? you get it though.)
- the crucible client talks to upstairs to like… do user-facing storage things
- the upstairs virtual device is divided into (fixed-size?) regions, and each region needs three associated instances of downstairs (three mirrors)
- upstairs talks to downstairs instances to retrieve block data and extra metadata
- there’s also a crucible “agent” that manages downstairs processes that i don’t want to run so i didn’t read much of it
(img src: i'm not sure. maybe adam from oxide?)
ok so how are you going to do it
alright. here’s what i’m looking to try at home:
i have two servers in my homelab that i will use for this. one is older and has an 8TB HDD array. one is newer and has a 16TB NVMe SSD array:
- the older one (“anchor”) runs more services and stores more data that i care about, so i would like it to run “upstairs”
- the newer one (“crystal”) is pretty much empty, so I can migrate all the data to the older server and try to use its SSD array to host some downstairs instances
both are running arch and using btrfs which is very different from the helios/zfs production setup that crucible is really made for. (this is most of the reason that i do not want to run the management agent)
and obviously, we miss out on fault tolerance here because all the data lives on one machine on only a handful of disks. but later, a much more
competent, richer, and more motivated future me will expand this system to a distributed group of mirrors.
thanks future me <3
anyway, here’s the plan:
- run some downstairs instances where the disks are
- run an upstairs instance where the disks aren’t
- run
crucible-nbd-serverto expose upstairs as a “network block device” - run
nbd-clientto expose a system block device via the nbd linux kernel module
so that’s like… a few layers of indirection. but it should be fine since a loopback socket is pretty much a pipe… right? let’s find out!!
oh yeah and between the two servers is like a 8ms network boundary (i have two home ISPs with separated networks) i hope that doesn’t kill perf lol
doing the thing
find out next episode when i finish this blog post